The information theory by Strømnes is divided into two parts. The first part contains memory models, two of them. They depict the memorizing of meaningless and meaningful material. The second part describes how to use combinations of words, i.e. how to communicate. Strømnes has named his theory the semiotic theory of imagery processes. It describes how information about spatial relationships is transmitted through verbal means.
Strømnes’ memory models
Strømnes (1974a) has presented two memory models. The first is a simple model for storing insignificant verbal material. However, this model cannot explain the learning of more languages. The second, complementary model, can also explain learning multiple languages. The core of the model is that it assumes its own inventory of words and meaningful symbols. With meaningful symbols Strømnes means images. The words are supposed to be arbitrarily selected signs (cf. de Saussure, 1966 and Arnheim, 1969).
Figure 1 illustrates the simple memory model. The model is meant to explain the remembrance of insignificant verbal material. At this point it is assumed that all words are different. Of course, this is not true for natural language, as words may have several meanings depending on the connection (see, e.g., Hunt & Agnoli, 1991). This problem can be solved by the latter model.
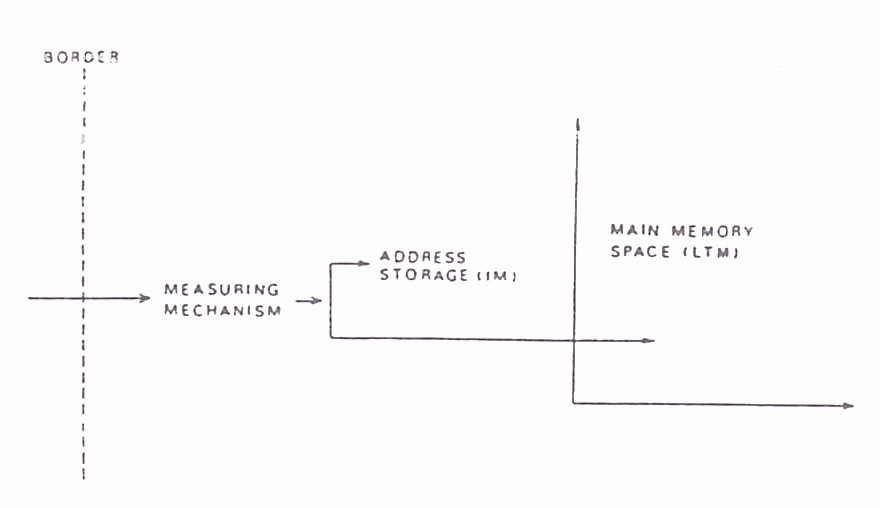
Fig. 1. A schematic model for storage of non-meaningful material. IM = intermediate memory, LTM = long term memory (Strømnes, 1974)
There is a border in the figure, through which there is the input channel to the measuring mechanism. The border describes the part of the organism in which the spoken word becomes its neural isomorph, its representation in the central nervous system. According to the above assumption, all neural representations in this model have a different physical nature. The measurement system is involved because things in the main memory need to be found quickly. Therefore, they must be in a clearly arranged simple address book space. Because all representations have a unique physical nature, this feature can be used for mechanical addressing. The size of the main memory is equal to the phonology of the language. The address storage collects the addresses that the measurement system has read. It also sends information to the main memory space and retrieves representations whose addresses are activated.
However, this simple model is not enough to solve the natural language storage problems. The test by Kolers (1966), in which he used bilingual subjects, clearly demonstrates this: the likelihood of remembering words in a bilingual word list did not depend on the physical form of the word (e.g. cheval or horse), but on the number of repetitions of the term “horse”. In tests using long word lists, the probability of remembering a particular word increases with the number of repetitions. According to the model in Figure 1, each word (cheval and horse) would have its own address and its own memory location. However, this model is not supported by the Kolers test result. The likelihood of remembering “cheval” and “horse” was the same as if it had been presented in only one language. The results can be explained by assuming that words relate to another type of representation. This second representation must have a different physical form than word representations and “bear” the meaning of word representations. In this model, words are called first-order representations and representations of meaning are called second-order representations. The second-order representation is assumed to be the image and it is also assumed that the representation of the second order, which was activated in the Kolers experiment, was an image of the horse. How this happens to a bilingual person is explained by the addition made to the model in Figure 2.
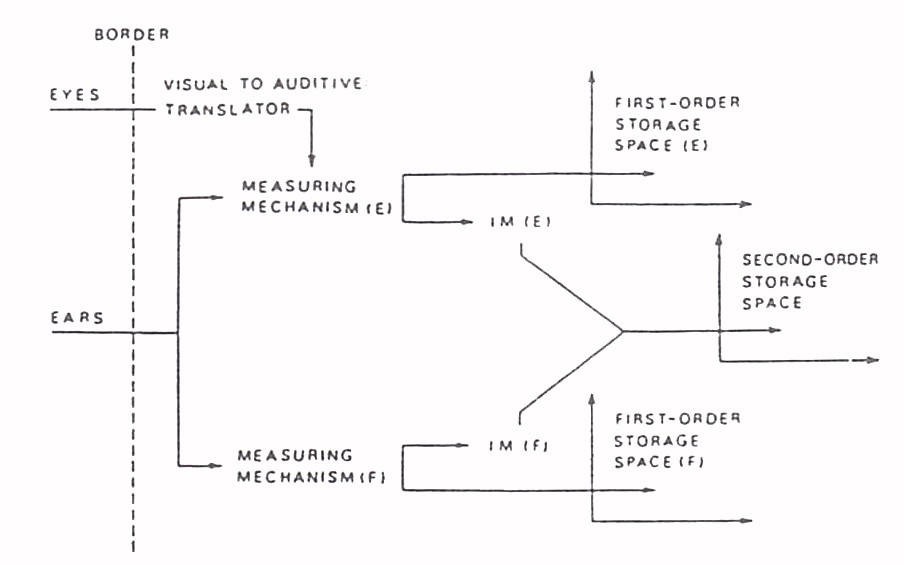
Fig. 2. A schematic model for storage of non-meaningful and meaningful material. E = mother tongue, F = acquired language (Strømnes, 1974).
In figure 2, a first-order and second-order storage space has been added to the model. The first-order memory space comprises the phonology of the tongue and the second-order memory space comprises images. In the figure, an input channel is drawn through the measurement system and the cache (IM = intermediate memory) to both the first and second-order memory space. According to Strømnes, this is a completely hypothetical solution and is based on the fact that it would be most practical to find (or to preserve) at one address representations of both the first and the second order. Thus, the word “horse” and the image it raises can be found at the same address. The main input channel is the ears, but there is another input channel eyes through the visual to auditive translator into the measurement system. This explains that when learning to read does not require learning new representations of the first and second degree, which would mean that learning to read would be a much slower process than it is in practice.
Figure 2 shows two first-order memory spaces. The first is marked with the F (“mother tongue”) and the other with the letter “E” (“learned language”). Letters could mean Finnish and English. Each has its own measurement system, and both are connected to the same second-order memory space. According to this model, in the Kolers experiment, the words “cheval” and “horse” activate the same level of representation – the image of the horse. The probability of remembering “horse” was the likelihood of the image of the horse becoming active. The prerequisite for obtaining this result is, of course, that the words of both languages can awaken the image of the person concerned. If this does not happen, the listener does not know the meaning of the word in that language and the representation of the second order is not activated. In this case, in the Kolers experiment, the likelihood of remembering such words would correspond to remembering insignificant material.
Understanding the language and its communicative use can now be considered in the light of the above model. According to this model: (1) first-order representations do not carry any psychological meaning at all, and (2) the second-order representations carry the psychological meaning and their physical form is different from that of their corresponding first-order representations. These statements are in line with the idea of de Saussure (1966) that the words of the language are arbitrary signs that have been agreed upon among people speaking a certain language. Since there is no isomorphic relationship between the word and the image it evokes, the words of several languages can awaken the same image in the listener, and vice versa: the same image can be conveyed by the words of several languages, e.g. tyttö, girl, Mädchen. The meaning of words is that they are able to awaken images in their listener.
As mentioned earlier, second-order representations are assumed to be images. Although this model explains how bilingual individuals remember individual words in a psychological experiment, it does not explain what happens when someone learns a language. In order for thinking to be possible, the images must be combined in some way. More on that in the next post….
REFERENCES
Arnheim, R. (1969) Visual thinking. Berkeley: University of California Press.
de Saussure, F. (1966) Course in general linguistics. New York: McGraw-Hill.
Hunt, E. & Agnoli, F. (1991) The Whorfian hypothesis: A cognitive psychology perspective. Psychological Review, 98, 377-389.
Kolers, P.A. (1966) Interlingual facilitation of short-term memory. Journal of Verbal Learning and Verbal Behavior, 5, 314-319.
Strømnes, F.J. (1974) Memory models and language comprehension. Scandinavian Journal of Psychology, 15, 26-32.